

Theoretical Aspects for Bayesian Predictions Based on Three-Parameter Burr-XII Distribution and Its Applications in Climatic Data
 ,
,  , and
, and
Abstract
:1. Introduction
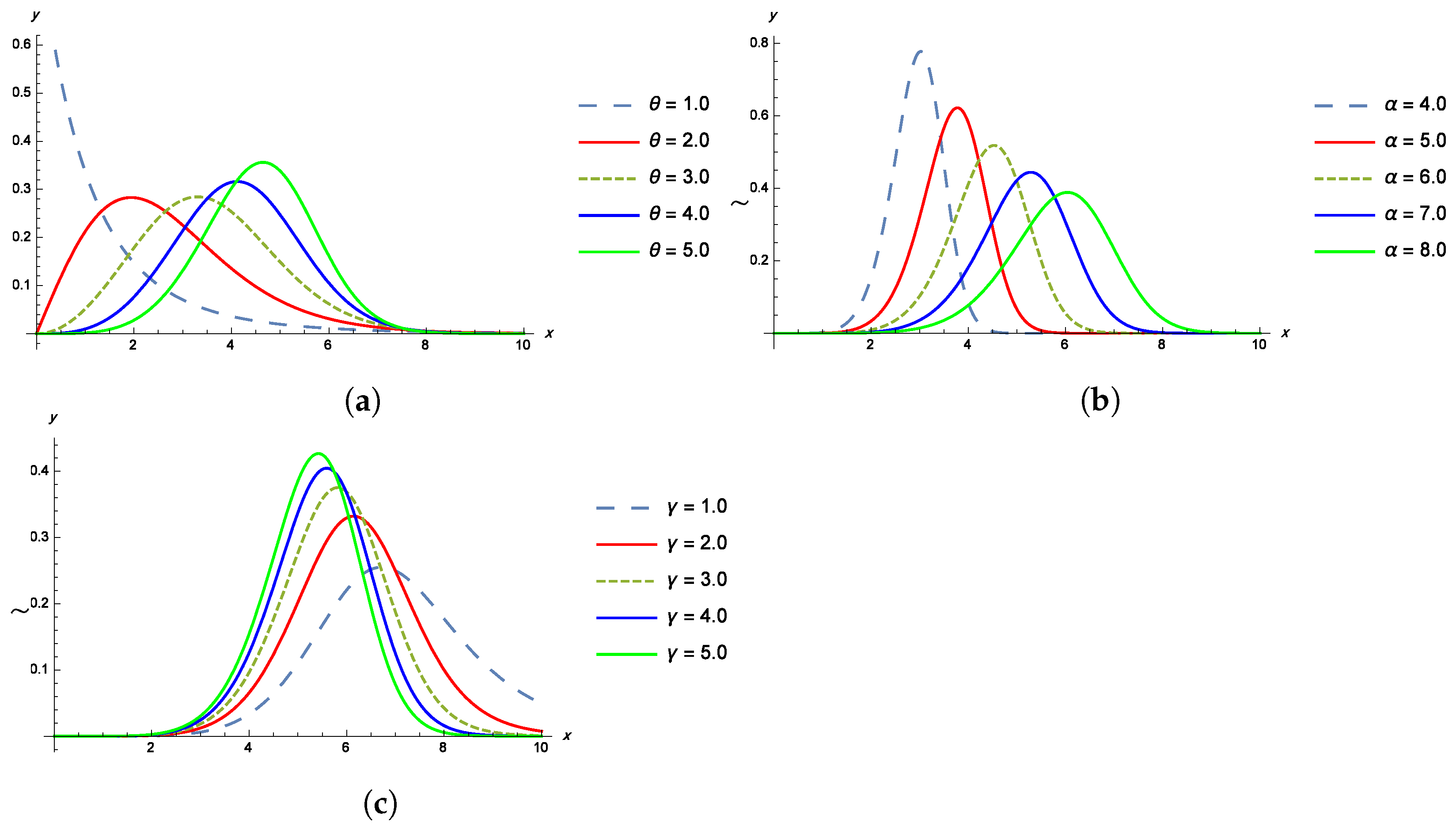
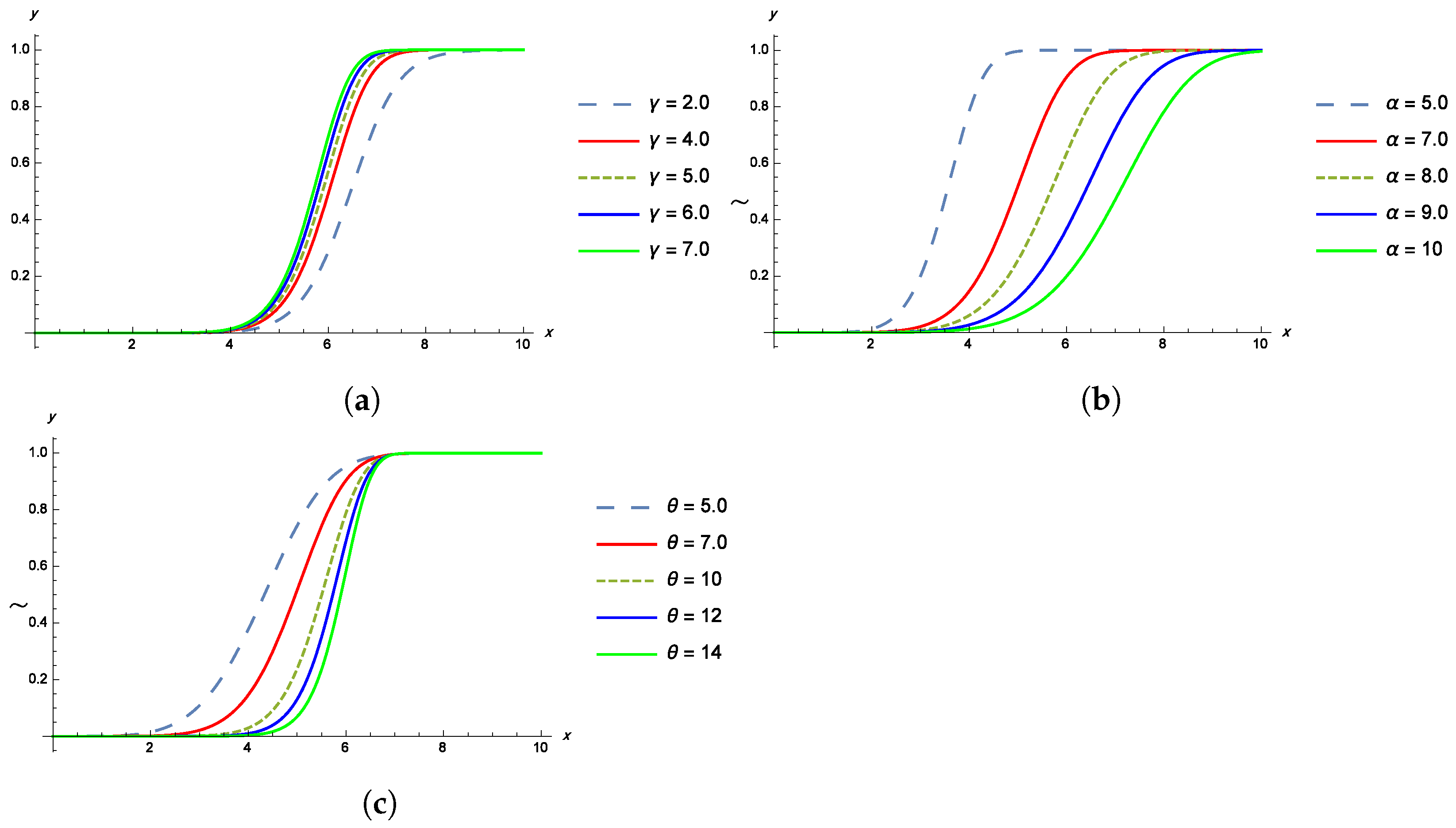
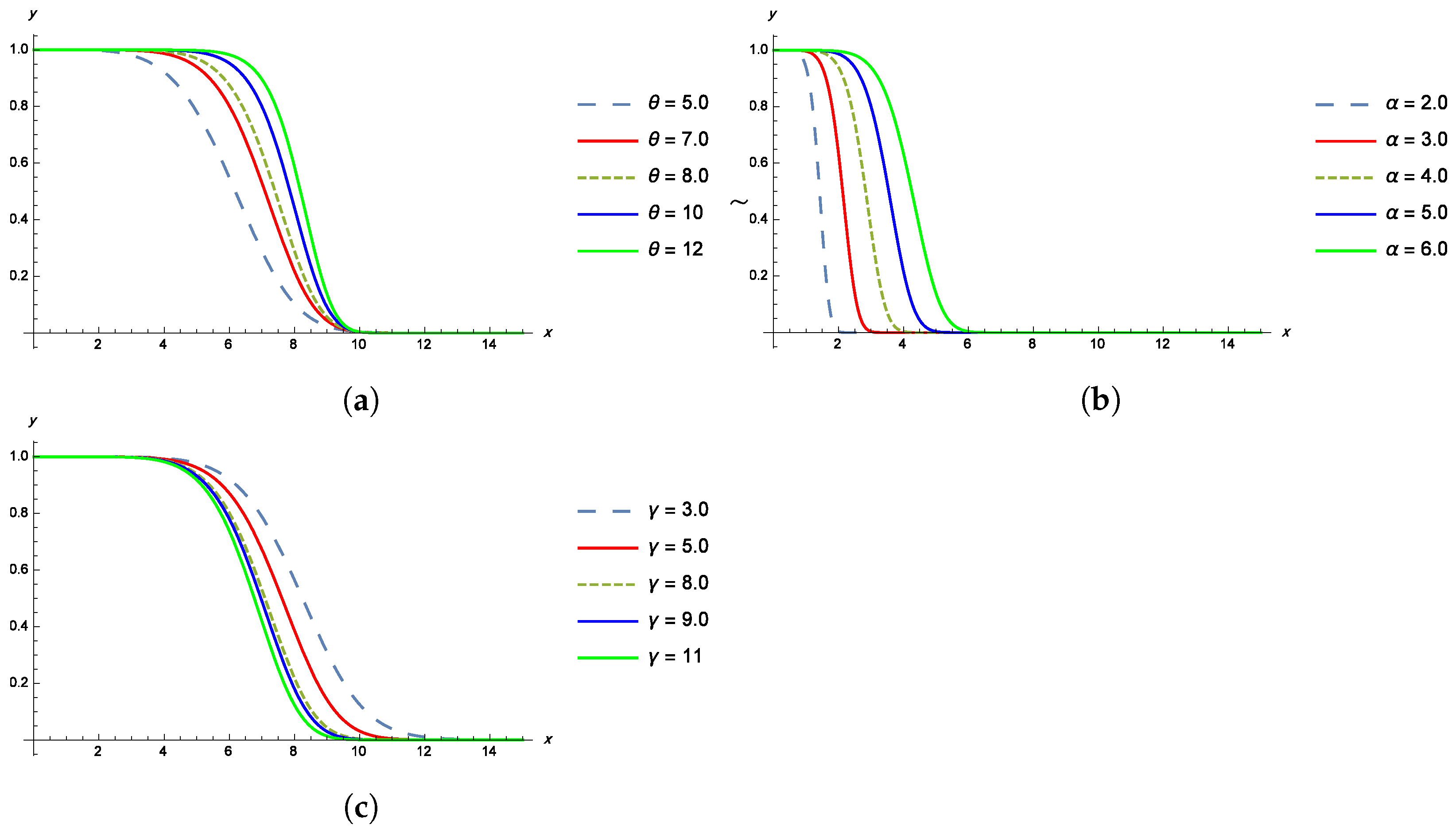
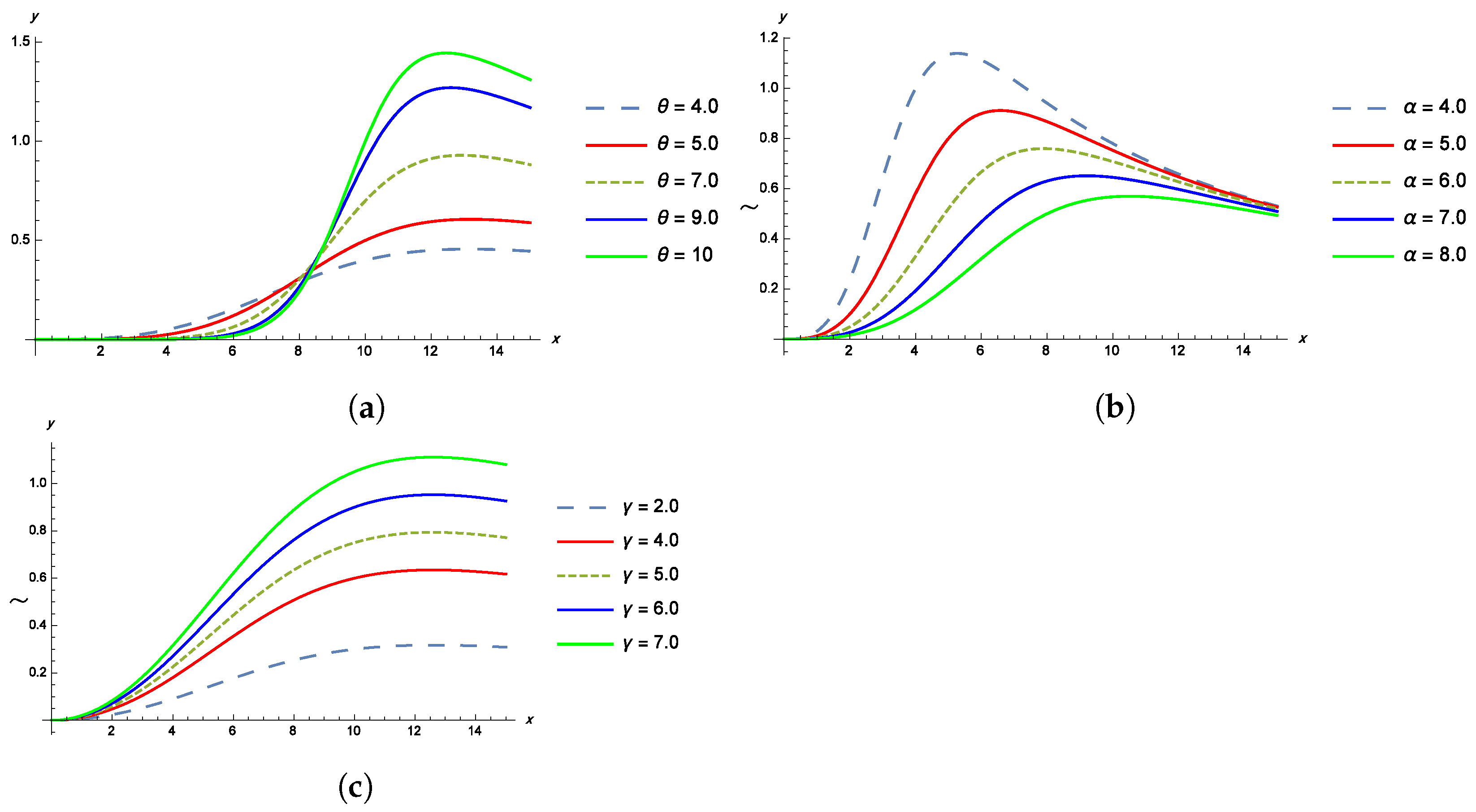
Properties of the TPBXIID
- The rth moment about the origin of a random variable Z distributed by a TPBXIID, denoted by , is the expected value of , symbolically,where
- The variance of TPBXIID can be written as
- The quantile of the TPBXIID can be defined as
- (I)
- ,
- (II)
- ,
- (III)
- ,
- (IV)
- ,
- (V)
- ,
- (VI)
- .
2. Approximate Confidence Interval
3. One-Sample Bayesian Prediction
4. Two-Sample Bayesian Prediction
5. MCMC Method
5.1. Estimation Based on Squared Error (SE) Loss Function
5.2. Estimation Based on Linear Exponential (LINEX) Loss Function
5.3. Estimation Based on General Entropy (GE) Loss Function
| Algorithm 1: Metropolis–Hasting within Gibbs sampling |
|
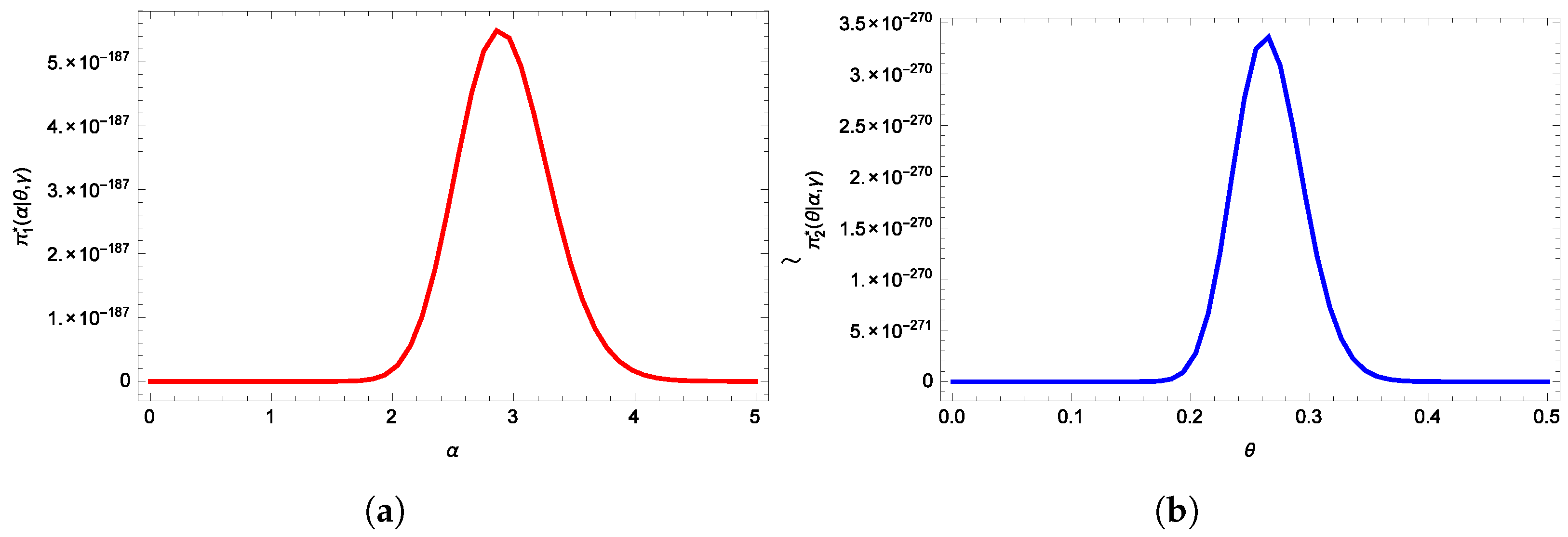
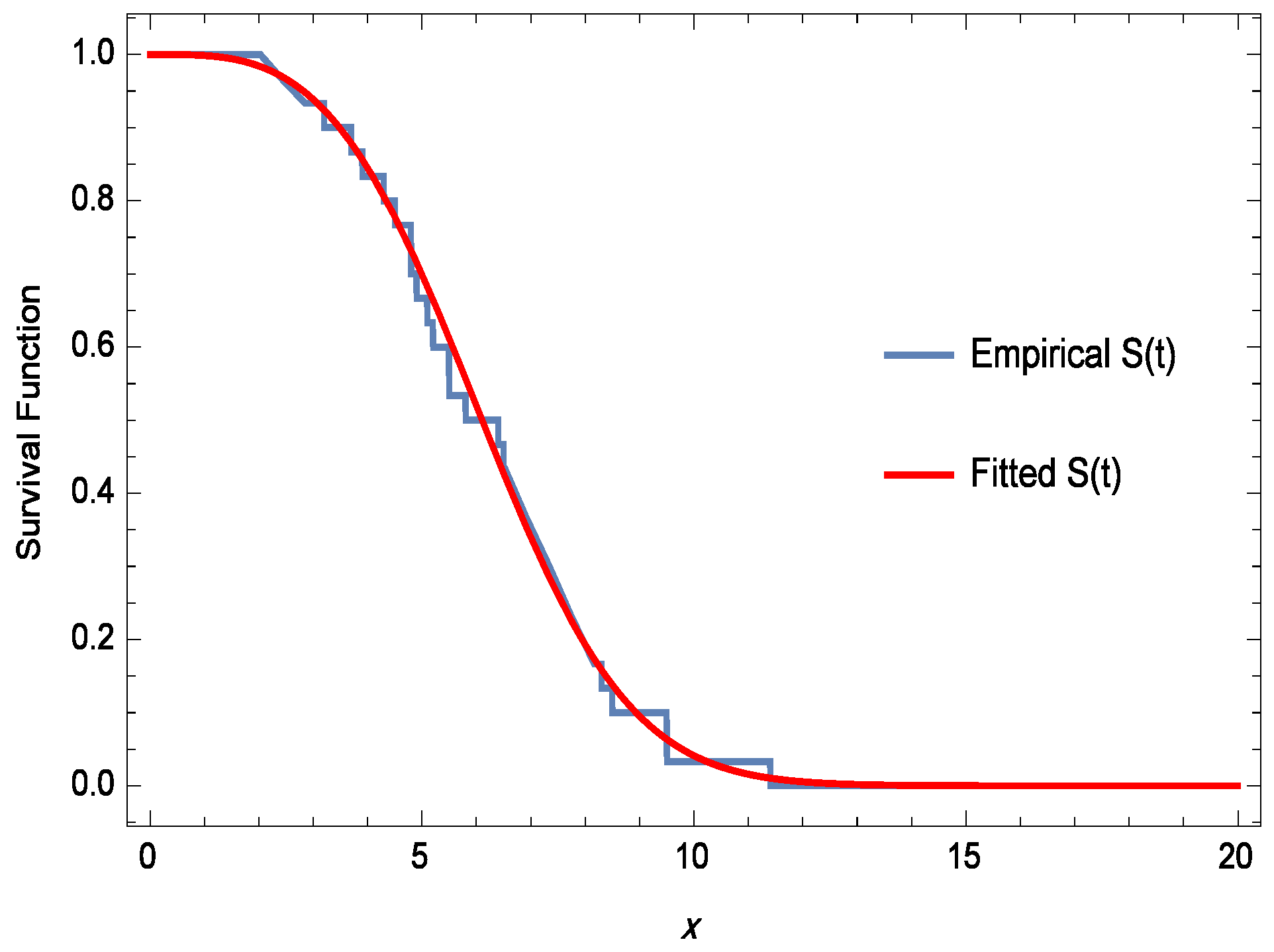
6. Applications
| 2.3 | 2.7 | 3.2 | 3.7 | 3.9 | 4.3 | 4.5 | 4.8 | 4.8 | 4.9 | 5.1 | 5.2 | 5.5 | 5.5 | 5.8 |
| 6.4 | 6.5 | 6.8 | 6.9 | 7 | 7.3 | 7.4 | 7.7 | 7.9. |
- I:
- . .
- II:
- . .
- III:
- . .
- IV:
- . .
- V:
- . .
- VI:
- . .
7. Simulation
- Based on the derived parameter values from Step 1, random samples are produced using the TPBXIID’s inverse cumulative distribution function. After that, these samples have been organised in ascending order.
- The values are calculated, where denotes a estimate (ML estimate or Bayesian estimate).
- A sample is generated using TPBXIID with the following parameter values: , , , and . Steps 1–6 are performed at least 1000 times. The simulation is run with various values for k, r, , and . , , , , and , are estimated using ML estimations, and the MSEs, CP, and length of CIs are calculated for and . Table 13, Table 14 and Table 15, show the results.
- Bayesian estimates are used to estimate , , , , and under the SE, LINEX, and GE loss functions. Informative gamma priors are used for the shape and scale parameters, with specific hyperparameters (, , , , , and ) when and . The results, including 95% CRIs, MSEs, CP, and length, are displayed in Table 13, Table 14 and Table 15.
- Furthermore, the MSE of the estimates is calculated using the following formula:
8. Conclusions
- The results presented in Table 1, Table 2, Table 3, Table 4, Table 5, Table 6, Table 7, Table 8, Table 9, Table 10, Table 11 and Table 12 reveal that the length of the prediction intervals increases with higher values of c. Specifically, Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6 indicate that the lower bounds are relatively insensitive to hyper-parameter specifications, while the upper bounds exhibit some sensitivity. Conversely, Table 7, Table 8, Table 9, Table 10, Table 11 and Table 12 demonstrate that both the lower and upper bounds are relatively insensitive to the specification of the hyper-parameters.
- Table 13, Table 14 and Table 15 reveal that the length of the credible intervals (CRIs) for the Bayes estimates of , , and are smaller than the corresponding lengths of the confidence intervals (CIs) of the MLEs. Additionally, the coverage probabilities (CP) of the Bayes estimates are greater than the corresponding CP of the MLEs.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| , , | Parameters of three-parameter Burr-XII distribution |
| Moment | |
| Variance of three-parameter Burr-XII distribution | |
| Inverse of cumulative distribution function | |
| Refers to the total number of failures in the test up to period B | |
| The stopping time point | |
| Fisher information matrix | |
| Hyper-parameters |
| Abbreviation | Meaning |
|---|---|
| UHCS | Unified Hybrid Censoring Scheme |
| TPBXIID | Three-Parameter Burr-XII Distribution |
| MCMC | Markov Chain Monte Carlo |
| Probability Density Function | |
| cdf | Cumulative Distribution Function |
| MLEs | Maximum Likelihood Estimators |
| ML | Maximum Likelihood |
| CIs | Confidence Intervals |
| SE | Squared Error Loss Function |
| LINEX | Linear Exponential Loss Function |
| GE | General Entrop Loss Function |
| MSE | Mean Squared Error |
| MAE | Mean Absolute Error |
| CP | Coverage Probability |
| K-S | Kolmogorov-Smirnov |
Appendix B
Appendix C
References
- Balakrishnan, N.; Rasouli, A.; Sanjari Farsipour, N. Exact likelihood inference based on an unified hybrid censored sample from the exponential distribution. J. Stat. Comput. Simul. 2008, 78, 475–788. [Google Scholar] [CrossRef]
- Burr, I.W. Cumulative frequency functions. Ann. Math. Stat. 1942, 13, 215–232. [Google Scholar] [CrossRef]
- Shao, Q. Notes on maximum likelihood estimation for the three-parameter Burr-XII distribution. Comput. Stat. Data Anal. 2004, 45, 675–687. [Google Scholar] [CrossRef]
- Wu, S.J.; Chen, Y.J.; Chang, C.T. Statistical inference based on progressively censored samples with random removals from the Burr type XII distribution. J. Stat. Comput. Simul. 2007, 77, 19–27. [Google Scholar] [CrossRef]
- Silva, G.O.; Ortega, E.M.M.; Garibay, V.C.; Barreto, M.L. Log-Burr-XII regression models with censored data. Comput. Stat. Data Anal. 2008, 52, 3820–3842. [Google Scholar] [CrossRef]
- Ganora, D.; Laio, F. Hydrological applications of the Burr distribution: Practical method for parameter estimation. J. Hydrol. Eng. 2015, 20, 04015024. [Google Scholar] [CrossRef]
- Cook, R.D.; Johnson, M.E. Generalized Burr-Pareto-Logistic distribution with application to a uranium exploration data set. Technometrics 1986, 28, 123–131. [Google Scholar] [CrossRef]
- Zimmer, W.J.J.; Keats, B.; Wang, F.K. The Burr-XII distribution in reliability analysis. J. Qual. Technol. 1998, 30, 386–394. [Google Scholar] [CrossRef]
- Tadikamalla, P.R. A look at the Burr and related distributions. Int. Stat. Rev. 1980, 48, 337–344. [Google Scholar] [CrossRef] [Green Version]
- Belaghi, R.A.; Asl, M.N. Estimation based on progressively Type-I hybrid censored data from the Burr-XII distribution. Stat. Pap. 2019, 60, 761–803. [Google Scholar] [CrossRef]
- Nasir, A.; Yousof, H.M.; Jamal, F.; Korkmaz, M.Ç. The exponentiated Burr-XII power series distribution: Properties and applications. Stats 2019, 2, 15–31. [Google Scholar] [CrossRef] [Green Version]
- Jamal, F.; Chesneau, C.; Nasir, M.A.; Saboor, A.; Altun, E.; Khan, M.A. On a modified Burr-XII distribution having flexible hazard rate shapes. Math. Slovaca 2020, 70, 193–212. [Google Scholar] [CrossRef]
- Sen, T.; Bhattacharya, R.; Pradhan, B.; Tripathi, Y.M. Statistical inference and Bayesian optimal life-testing plans under Type-II unified hybrid censoring scheme. Qual Reliab. Eng Int. 2021, 37, 78–89. [Google Scholar] [CrossRef]
- Dutta, S.; Kayal, S. Bayesian and non-Bayesian inference of Weibull lifetime model based on partially observed competing risks data under unified hybrid censoring scheme. Qual. Reliab. Eng. Int. 2022, 38, 3867–3891. [Google Scholar] [CrossRef]
- Dutta, S.; Ng, H.K.T.; Kayal, S. Inference for a general family of inverted exponentiated distributions under unified hybrid censoring with partially observed competing risks data. J. Comput. Appl. Math. 2023, 422, 114934. [Google Scholar] [CrossRef]
- Sagrillo, M.; Guerra, R.R.; Machado, R.; Bayer, F.M. A generalized control chart for anomaly detection in SAR imagery. Comput. Ind. Eng. 2023, 177, 109030. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Shafay, A.R. One- and two-Sample Bayesian prediction intervals based on Type-II hybrid censored data. Commun. Stat. Theory Method 2012, 41, 1511–1531. [Google Scholar] [CrossRef]
- AL-Hussaini, E.K.; Ahmad, A.A. On Bayesian predictive distributions of generalized order statistics. Metrika 2003, 57, 165–176. [Google Scholar] [CrossRef]
- Shafay, A.R.; Balakrishnan, N. One- and two-sample Bayesian prediction intervals based on Type-I hybrid censored data. Commun. Stat. Simul. Comput. 2012, 41, 65–88. [Google Scholar] [CrossRef]
- Shafay, A.R. Bayesian estimation and prediction based on generalized Type-II hybrid censored sample. J. Stat. Comput. Simul. 2015, 86, 1970–1988. [Google Scholar] [CrossRef]
- Shafay, A.R. Bayesian estimation and prediction based on generalized Type-I hybrid censored sample. Commun. Stat. Theory Methods 2016, 46, 4870–4887. [Google Scholar] [CrossRef]
- Ateya, S.F.; Alghamdi, A.S.; Mousa, A.A.A. Future Failure Time Prediction Based on a Unified Hybrid Censoring Scheme for the Burr-X Model with Engineering Applications. Mathematics 2022, 10, 1450. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equations of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1091. [Google Scholar] [CrossRef] [Green Version]
- Arnold, B.C.; Balakrishnan, N.; Nagaraja, H.N. A First Course in Order Statistics; Wiley: New York, NY, USA, 1992. [Google Scholar]
- Varian, H.R. A Bayesian Approach to Real Estate Assessment; North Holland: Amsterdam, The Netherlands, 1975; pp. 195–208. [Google Scholar]
- Zellner, A. Bayesian estimation and prediction using asymmetric loss functions. J. Am. Assoc. Nurse Pract. 1986, 81, 446–551. [Google Scholar] [CrossRef]
- Basu, A.P.; Ebrahimi, N. Bayesian Approach to Life Testingand Reliability Estimation Using Asymmetric Loss Function. J. Statist. Plann. Infer. 1991, 29, 21–31. [Google Scholar] [CrossRef]






| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 25 | 3.8736 | 8.5333 | 4.6596 | 4.8556 | 10.5962 | 5.7405 |
| 26 | 3.2825 | 8.7000 | 5.4174 | 3.2000 | 11.4014 | 8.2014 |
| 27 | 3.21953 | 11.9083 | 8.6888 | 3.26769 | 11.8520 | 8.5843 |
| 28 | 4.5602 | 13.1513 | 8.5910 | 7.1997 | 15.905 | 8.70527 |
| 29 | 5.2025 | 16.5493 | 11.3467 | 4.90806 | 14.7077 | 9.79967 |
| 30 | 6.9177 | 18.9000 | 11.9823 | 6.95388 | 18.9000 | 11.9461 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 25 | 7.7869 | 9.0600 | 1.2731 | 4.8009 | 9.5451 | 4.7441 |
| 26 | 4.1457 | 8.6956 | 4.5498 | 4.2223 | 9.7665 | 5.5442 |
| 27 | 4.8663 | 10.2715 | 5.4052 | 4.2000 | 11.1129 | 6.9129 |
| 28 | 4.2000 | 10.5000 | 6.3000 | 4.3893 | 11.5000 | 7.1107 |
| 29 | 5.2220 | 12.5220 | 7.3000 | 10.2321 | 20.7879 | 10.5558 |
| 30 | 9.2123 | 19.7756 | 10.5633 | 11.2011 | 23.4833 | 12.2822 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 25 | 5.70308 | 11.1037 | 5.40059 | 6.1153 | 7.7294 | 1.6140 |
| 26 | 3.3830 | 12.2610 | 8.8780 | 4.0868 | 9.4781 | 5.3912 |
| 27 | 4.2000 | 14.4222 | 10.2222 | 4.9743 | 10.7000 | 5.7257 |
| 28 | 5.19673 | 17.8434 | 12.6467 | 8.9686 | 22.563 | 13.5944 |
| 29 | 5.9047 | 19.9451 | 14.0403 | 7.9907 | 24.3793 | 16.3885 |
| 30 | 6.0000 | 23.2599 | 17.2599 | 6.1427 | 25.8677 | 19.7250 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 25 | 3.7396 | 8.7000 | 4.9604 | 3.4876 | 8.7000 | 5.2124 |
| 26 | 5.5984 | 12.6137 | 7.0152 | 4.9300 | 9.0091 | 4.0791 |
| 27 | 6.2781 | 13.5789 | 7.3007 | 6.6121 | 13.9462 | 7.3341 |
| 28 | 6.6000 | 13.9513 | 7.3512 | 6.7000 | 17.4056 | 9.8056 |
| 29 | 7.6600 | 15.9700 | 8.3100 | 8.6611 | 18.9733 | 10.3122 |
| 30 | 9.2331 | 20.2556 | 11.0225 | 10.2121 | 23.2241 | 13.0120 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 25 | 5.53617 | 7.78096 | 2.24479 | 5.3643 | 8.1147 | 2.7504 |
| 26 | 5.6003 | 10.7000 | 5.0997 | 5.6000 | 11.7492 | 6.1491 |
| 27 | 5.2000 | 12.2046 | 7.0045 | 5.5276 | 13.4346 | 7.9069 |
| 28 | 5.4400 | 15.5000 | 10.0600 | 5.4403 | 15.3444 | 9.9041 |
| 29 | 9.1223 | 22.2556 | 13.1333 | 10.1000 | 22.9920 | 12.8920 |
| 30 | 10.0022 | 23.8766 | 13.8744 | 10.9548 | 24.5470 | 13.5922 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 25 | 4.32166 | 8.7000 | 4.37834 | 4.4000 | 13.1678 | 8.7677 |
| 26 | 5.1000 | 10.5178 | 5.4177 | 6.1522 | 11.4733 | 5.3211 |
| 27 | 5.9582 | 11.5029 | 5.5447 | 5.6235 | 12.9546 | 7.3311 |
| 28 | 6.60333 | 13.8686 | 7.2652 | 6.6045 | 13.9588 | 7.3543 |
| 29 | 7.6600 | 16.3534 | 8.6933 | 7.6611 | 15.9733 | 8.3122 |
| 30 | 10.2000 | 33.5934 | 23.3934 | 10.5364 | 25.7896 | 15.2532 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 1 | 0.2486 | 3.3945 | 3.1459 | 0.3254 | 3.5413 | 3.2159 |
| 2 | 0.3550 | 4.8725 | 4.5175 | 0.5801 | 4.0241 | 3.4440 |
| 3 | 0.4570 | 5.1510 | 4.6937 | 0.5845 | 4.2241 | 3.6396 |
| 4 | 0.4573 | 5.4513 | 4.9940 | 1.6295 | 5.3540 | 3.7245 |
| 5 | 4.0220 | 11.8667 | 7.8446 | 1.9025 | 11.8667 | 9.9642 |
| 6 | 5.4547 | 13.9687 | 8.5139 | 2.3426 | 13.9687 | 11.6261 |
| 7 | 5.4809 | 14.9673 | 9.4864 | 2.3742 | 14.9673 | 12.5931 |
| 8 | 5.5550 | 15.2786 | 9.7235 | 2.4035 | 15.2786 | 12.8751 |
| 9 | 5.6388 | 15.7427 | 10.1039 | 2.49025 | 15.7427 | 13.2524 |
| 10 | 6.6691 | 19.8596 | 13.1904 | 4.56972 | 19.8596 | 15.2899 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 1 | 0.1031 | 1.6322 | 1.5291 | 0.1864 | 2.0145 | 1.8281 |
| 2 | 0.2548 | 4.6584 | 4.4036 | 0.3015 | 5.1236 | 4.8221 |
| 3 | 0.3647 | 5.6643 | 5.2996 | 0.3647 | 5.48984 | 5.1251 |
| 4 | 0.6959 | 7.4227 | 6.7268 | 0.9823 | 6.2548 | 5.2725 |
| 5 | 1.2144 | 12.8667 | 11.6523 | 1.1458 | 11.2659 | 10.1201 |
| 6 | 1.3675 | 13.9687 | 12.6012 | 1.3675 | 13.9687 | 12.6012 |
| 7 | 1.3789 | 14.9673 | 13.5884 | 1.3789 | 14.9673 | 13.5884 |
| 8 | 1.4563 | 15.2786 | 13.8223 | 1.4563 | 15.2786 | 13.8223 |
| 9 | 1.5134 | 15.7427 | 14.2293 | 1.4435 | 16.5780 | 15.1345 |
| 10 | 4.69475 | 19.8596 | 15.1649 | 4.5390 | 19.8596 | 15.3206 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 1 | 0.2031 | 3.3215 | 3.1184 | 0.1845 | 3.1853 | 3.0008 |
| 2 | 0.2544 | 5.1221 | 4.8677 | 0.2345 | 5.1203 | 4.8858 |
| 3 | 0.2739 | 5.5670 | 5.2931 | 0.2739 | 5.40102 | 5.1271 |
| 4 | 0.2942 | 8.6548 | 8.3606 | 0.3542 | 7.9549 | 7.6007 |
| 5 | 1.1309 | 12.4892 | 11.3583 | 0.9984 | 11.9856 | 10.9872 |
| 6 | 1.1987 | 13.3486 | 12.1499 | 1.1236 | 14.6985 | 13.5749 |
| 7 | 1.2056 | 14.3345 | 13.1289 | 1.2015 | 15.0114 | 13.8099 |
| 8 | 1.2544 | 15.4453 | 14.1909 | 1.2544 | 15.4453 | 14.1909 |
| 9 | 1.3567 | 15.5483 | 14.1916 | 2.1436 | 16.0153 | 13.8717 |
| 10 | 2.0577 | 20.1125 | 18.0548 | 4.4570 | 20.1125 | 15.6555 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 1 | 0.1175 | 1.6437 | 1.5262 | 0.1824 | 2.0843 | 1.9019 |
| 2 | 0.1548 | 5.4539 | 5.2991 | 0.3546 | 4.9875 | 4.6329 |
| 3 | 0.2212 | 5.5994 | 5.3782 | 0.4256 | 6.1235 | 5.6979 |
| 4 | 0.2712 | 8.5504 | 8.2792 | 0.6943 | 7.3942 | 6.6999 |
| 5 | 1.2947 | 12.3378 | 11.0431 | 1.2200 | 11.1996 | 10.0896 |
| 6 | 1.3568 | 13.2232 | 11.8664 | 1.3568 | 13.2232 | 11.8664 |
| 7 | 1.5789 | 14.1177 | 12.5388 | 1.6548 | 15.3214 | 13.6666 |
| 8 | 1.7896 | 14.4596 | 12.6700 | 1.7896 | 15.8997 | 14.1101 |
| 9 | 1.8087 | 16.1478 | 14.3391 | 2.4695 | 17.3258 | 14.8563 |
| 10 | 3.3842 | 20.0125 | 16.6282 | 4.24655 | 20.0125 | 15.7659 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 1 | 0.1234 | 3.6400 | 3.5166 | 0.1234 | 1.8654 | 1.7420 |
| 2 | 0.2111 | 5.2222 | 5.0111 | 0.2103 | 4.8756 | 4.6653 |
| 3 | 0.2548 | 5.2870 | 5.0322 | 0.2548 | 5.0833 | 4.8285 |
| 4 | 0.2684 | 6.8894 | 6.6210 | 0.3124 | 5.9874 | 5.6750 |
| 5 | 1.0325 | 12.3654 | 11.3329 | 0.9988 | 11.9879 | 109891 |
| 6 | 1.1943 | 13.3564 | 12.1621 | 1.1045 | 13.9876 | 12.8831 |
| 7 | 1.2534 | 14.6231 | 13.3697 | 1.2534 | 14.6231 | 13.3697 |
| 8 | 1.3230 | 15.6231 | 14.3001 | 1.2765 | 14.9849 | 13.7089 |
| 9 | 1.5423 | 16.6844 | 15.1421 | 1.2948 | 15.6813 | 14.3865 |
| 10 | 3.11574 | 20.3698 | 17.2541 | 2.8992 | 18.3698 | 15.4705 |
| Non-Informative Prior | Informative Prior | |||||
|---|---|---|---|---|---|---|
| s | Lower | Upper | Length | Lower | Upper | Length |
| 1 | 0.2111 | 1.2896 | 1.0785 | 0.2245 | 2.0111 | 1.7866 |
| 2 | 0.2214 | 4.4564 | 4.2350 | 0.2456 | 3.2354 | 2.9898 |
| 3 | 0.2636 | 5.2140 | 4.9504 | 0.2712 | 3.3147 | 3.0435 |
| 4 | 0.3214 | 7.4564 | 7.1352 | 0.2745 | 3.3257 | 3.0512 |
| 5 | 0.4686 | 11.8986 | 11.4300 | 0.9987 | 12.8493 | 11.8506 |
| 6 | 1.2109 | 13.6879 | 12.4770 | 1.3568 | 13.2232 | 11.8664 |
| 7 | 1.2653 | 14.2364 | 12.9711 | 1.5789 | 14.1177 | 12.5388 |
| 8 | 1.3345 | 14.4486 | 13.1141 | 1.7896 | 15.8997 | 14.1101 |
| 9 | 1.4644 | 16.4587 | 14.9943 | 1.8087 | 16.1478 | 14.3391 |
| 10 | 3.0390 | 20.7695 | 17.7305 | 3.8582 | 20.0125 | 16.1542 |
| Cases | r | k | |||||||||||
| MLE | MCMC | ||||||||||||
| MSE | Length | CP | SE | LINEX | GE | Length | CP | ||||||
| a = −4 | a = 4 | a = −4 | a = 4 | ||||||||||
| I | 77 | 75 | 10.00 | 0.4031 | 0.7854 | 0.8230 | 0.4321 | 0.4328 | 0.4318 | 0.4317 | 0.4315 | 0.0055 | 0.933 |
| 79 | 75 | 10.50 | 0.2154 | 0.5524 | 0.850 | 0.3877 | 0.3879 | 0.3875 | 0.3870 | 0.3866 | 0.0035 | 0.922 | |
| II | 84 | 75 | 10.60 | 0.5278 | 0.7887 | 0.863 | 0.5278 | 0.5279 | 0.5275 | 0.5265 | 0.5214 | 0.0034 | 0.935 |
| 88 | 75 | 10.70 | 0.5030 | 0.7542 | 0.869 | 0.3637 | 0.3635 | 0.3634 | 0.3638 | 0.3632 | 0.0020 | 0.970 | |
| III | 90 | 75 | 11.00 | 0.3988 | 0.7190 | 0.864 | 0.3980 | 0.3977 | 0.3970 | 0.3966 | 0.3711 | 0.0022 | 0.928 |
| 95 | 75 | 11.50 | 0.2248 | 0.2249 | 0.895 | 0.2254 | 0.2211 | 0.2233 | 0.2214 | 0.2200 | 0.0012 | 0.955 | |
| Cases | r | k | |||||||||||
| MLE | MCMC | ||||||||||||
| MSE | Length | CP | SE | LINEX | GE | Length | CP | ||||||
| a = −4 | a = 4 | a = −4 | a = 4 | ||||||||||
| IV | 96 | 80 | 13.00 | 0.3221 | 0.5321 | 0.871 | 0.3740 | 0.3744 | 0.3630 | 0.3622 | 0.3621 | 0.0029 | 0.923 |
| 96 | 85 | 13.50 | 0.2678 | 0.7854 | 0.823 | 0.2622 | 0.2534 | 0.2532 | 0.2531 | 0.2432 | 0.0025 | 0.933 | |
| V | 96 | 90 | 12.10 | 0.4532 | 0.5686 | 0.866 | 0.4442 | 0.4432 | 0.4321 | 0.4312 | 0.4254 | 0.0044 | 0.911 |
| 96 | 92 | 12.20 | 0.2654 | 0.6547 | 0.857 | 0.2621 | 0.2547 | 0.2544 | 0.2533 | 0.2522 | 0.0022 | 0.933 | |
| VI | 96 | 93 | 11.00 | 0.5554 | 0.7580 | 0.844 | 0.5523 | 0.5522 | 0.5512 | 0.5421 | 0.5345 | 0.0020 | 0.970 |
| 96 | 93 | 11.50 | 0.2897 | 0.5229 | 0.888 | 0.2977 | 0.2976 | 0.2970 | 0.2944 | 0.2854 | 0.0030 | 0.961 | |
| Cases | r | k | |||||||||||
| MLE | MCMC | ||||||||||||
| MSE | Length | CP | SE | LINEX | GE | Length | CP | ||||||
| a = −4 | a = 4 | a = −4 | a = 4 | ||||||||||
| I | 77 | 75 | 10.00 | 0.7435 | 0.8577 | 0.877 | 0.7044 | 0.6622 | 0.6255 | 0.6240 | 0.6001 | 0.0970 | 0.900 |
| 79 | 75 | 10.50 | 0.7177 | 0.5654 | 0.853 | 0.5554 | 0.5447 | 0.5432 | 0.5324 | 0.5100 | 0.083 | 0.978 | |
| II | 84 | 75 | 10.60 | 0.7577 | 0.5856 | 0.850 | 0.5477 | 0.5423 | 0.5322 | 0.4550 | 0.5420 | 0.0541 | 0.945 |
| 88 | 75 | 10.70 | 0.6522 | 0.5541 | 0.865 | 0.4860 | 0.4650 | 0.4568 | 0.4321 | 0.4258 | 0.0452 | 0.972 | |
| III | 90 | 75 | 11 | 0.6245 | 0.9200 | 0.852 | 0.5582 | 0.5644 | 0.5333 | 0.5422 | 0.5120 | 0.0359 | 0.923 |
| 95 | 75 | 11.50 | 0.5444 | 0.8840 | 0.843 | 0.5555 | 0.5445 | 0.4555 | 0.4452 | 0.4542 | 0.0230 | 0.976 | |
| Cases | r | k | |||||||||||
| MLE | MCMC | ||||||||||||
| MSE | Length | CP | SE | LINEX | GE | Length | CP | ||||||
| a = −4 | a = 4 | a = −4 | a = 4 | ||||||||||
| IV | 96 | 80 | 13.00 | 0.9877 | 0.8888 | 0.821 | 0.9695 | 0.9260 | 0.9160 | 0.9157 | 0.9135 | 0.0757 | 0.929 |
| 96 | 85 | 13.50 | 0.8398 | 0.8228 | 0.865 | 0.8277 | 0.8129 | 0.8020 | 0.8002 | 0.7039 | 0.0488 | 0.948 | |
| V | 96 | 90 | 12.10 | 0.76400 | 0.8849 | 0.846 | 0.7548 | 0.7544 | 0.7441 | 0.7423 | 0.7390 | 0.0445 | 0.989 |
| 96 | 92 | 12.20 | 0.6470 | 0.5179 | 0.869 | 0.6687 | 0.6647 | 0.6547 | 0.6467 | 0.6321 | 0.0427 | 0.992 | |
| VI | 96 | 93 | 11.00 | 0.5647 | 0.4512 | 0.833 | 0.5620 | 0.5230 | 0.5220 | 0.5212 | 0.5048 | 0.0780 | 0.915 |
| 96 | 95 | 11.50 | 0.4587 | 0.8400 | 0.878 | 0.4487 | 0.4321 | 0.4213 | 0.4125 | 0.4114 | 0.0658 | 0.949 | |
| Cases | r | k | |||||||||||
| MLE | MCMC | ||||||||||||
| MSE | Length | CP | SE | LINEX | GE | Length | CP | ||||||
| a = −4 | a = 4 | a = −4 | a = 4 | ||||||||||
| I | 77 | 75 | 10.00 | 0.7771 | 0.6600 | 0.859 | 0.5260 | 0.5310 | 0.5240 | 0.4920 | 0.3828 | 0.0750 | 0.931 |
| 79 | 75 | 10.50 | 0.7360 | 0.4276 | 0.865 | 0.4924 | 0.5251 | 0.4484 | 0.4430 | 0.3991 | 0.0612 | 0.988 | |
| II | 84 | 75 | 10.60 | 0.5333 | 0.8411 | 0.841 | 0.5312 | 0.4555 | 0.4388 | 0.4256 | 0.4123 | 0.0880 | 0.942 |
| 88 | 75 | 10.70 | 0.4674 | 0.6978 | 0.858 | 0.4860 | 0.4235 | 0.4912 | 0.3800 | 0.3788 | 0.0770 | 0.989 | |
| III | 90 | 75 | 11.00 | 0.2344 | 0.4320 | 0.800 | 0.3210 | 0.2301 | 0.2300 | 0.2287 | 0.2254 | 0.0740 | 0.954 |
| 95 | 75 | 11.50 | 0.2154 | 0.4215 | 0.822 | 0.2236 | 0.2221 | 0.2214 | 0.2201 | 0.2198 | 0.2112 | 0.987 | |
| Cases | r | k | |||||||||||
| MLE | MCMC | ||||||||||||
| MSE | Length | CP | SE | LINEX | GE | Length | CP | ||||||
| a = −4 | a = 4 | a = −4 | a = 4 | ||||||||||
| IV | 96 | 80 | 13.00 | 0.3245 | 0.3580 | 0.887 | 0.3214 | 0.3212 | 0.3211 | 0.3210 | 0.3199 | 0.0231 | 0.919 |
| 96 | 85 | 12.50 | 03210 | 0.3459 | 0.888 | 0.3154 | 0.3124 | 0.3122 | 0.3112 | 0.3111 | 0.0211 | 0.942 | |
| V | 96 | 90 | 12.10 | 0.4489 | 0.4888 | 0.863 | 0.4465 | 0.4456 | 0.4423 | 0.4359 | 0.4354 | 0.0200 | 0.939 |
| 96 | 92 | 12.20 | 0.4299 | 0.4211 | 0.802 | 0.4125 | 0.4112 | 0.4109 | 0.4105 | 0.4102 | 0.4100 | 0.962 | |
| VI | 96 | 93 | 11.00 | 0.3599 | 0.4599 | 0.828 | 0.3354 | 0.3269 | 0.3215 | 0.3211 | 0.3210 | 0.0265 | 0.978 |
| 96 | 95 | 11.50 | 0.3698 | 0.5480 | 0.844 | 0.3548 | 0.3544 | 0.3522 | 0.3469 | 0.3354 | 0.0235 | 0.987 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasaballah, M.M.; Al-Babtain, A.A.; Hossain, M.M.; Bakr, M.E. Theoretical Aspects for Bayesian Predictions Based on Three-Parameter Burr-XII Distribution and Its Applications in Climatic Data. Symmetry 2023, 15, 1552. https://doi.org/10.3390/sym15081552
Hasaballah MM, Al-Babtain AA, Hossain MM, Bakr ME. Theoretical Aspects for Bayesian Predictions Based on Three-Parameter Burr-XII Distribution and Its Applications in Climatic Data. Symmetry. 2023; 15(8):1552. https://doi.org/10.3390/sym15081552
Chicago/Turabian StyleHasaballah, Mustafa M., Abdulhakim A. Al-Babtain, Md. Moyazzem Hossain, and Mahmoud E. Bakr. 2023. "Theoretical Aspects for Bayesian Predictions Based on Three-Parameter Burr-XII Distribution and Its Applications in Climatic Data" Symmetry 15, no. 8: 1552. https://doi.org/10.3390/sym15081552
APA StyleHasaballah, M. M., Al-Babtain, A. A., Hossain, M. M., & Bakr, M. E. (2023). Theoretical Aspects for Bayesian Predictions Based on Three-Parameter Burr-XII Distribution and Its Applications in Climatic Data. Symmetry, 15(8), 1552. https://doi.org/10.3390/sym15081552